PinnedApache Spark: 5 Performance Optimization TipsInteresting and specific lessons learned from experienceJul 31, 2019Jul 31, 2019
PinnedPartition Management in HadoopOur solution to the Hadoop small files problemMay 27, 2020May 27, 2020
PinnedDefend Your Infrastructure — Handling 3,000 Hungry UsersWhy is it so important to track your users’ queries, and how we do it?Feb 14, 2019Feb 14, 2019
Firebolt — The new kid on the (data warehousing) blockA short description of Firebolt, for not-so-technical peopleMay 23, 2021May 23, 2021
SPOT: Is Spotify a good stock to buy?A human-readable stock analysis, from a rational perspectiveDec 26, 2020Dec 26, 2020
Impala Discussion With The Product Manager (Greg Rahn)Q&A session on specific issues that bothered usAug 31, 20181Aug 31, 20181
5 Main Missing Features in Impala (Opinion)A letter to the developers and product manager of ImpalaAug 15, 20183Aug 15, 20183
Hotspotting In Hadoop — Impala Case StudyWhy Small Frequently-Queried Tables Shouldn’t Be Stored In HDFS?Apr 13, 20182Apr 13, 20182
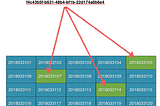
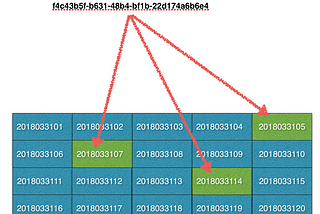
Partition Index - Selective Queries On Really Big TablesHow to make your selective queries run 100x faster?Apr 1, 20181Apr 1, 20181
Apache Impala: My Insights and Best PracticesHow did we make our Impala run faster?Mar 20, 20183Mar 20, 20183